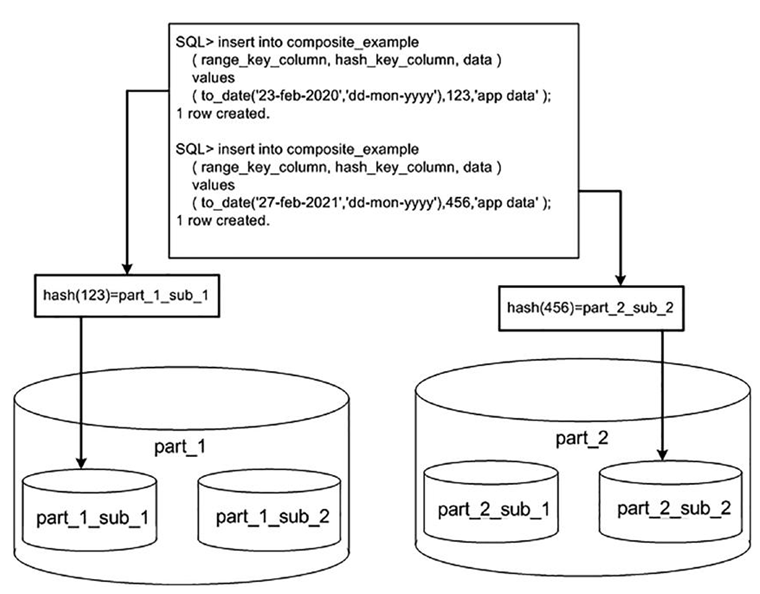
Interval partitioning is very similar to range partitioning described previously—in fact, it starts with a range partitioned table but adds a rule (the interval) to the definition so the database knows how to add partitions in the future.
The goal of interval partitioning is to create new partitions for data—if, and only if, data exists for a given partition and only when that data arrives in the database. In other words, to remove the need to pre- create partitions for data, to allow the data itself to create the partition as it is inserted.
To use interval partitioning, you start with a range partitioned table without a MAXVALUE partition and specify an interval to add to the upper bound, the highest value of that partitioned table to create a new range.
You need to have a table that is range partitioned on a single column that permits adding a NUMBER or INTERVAL type to it (e.g., a table partitioned by a VARCHAR2 field cannot be interval partitioned; there is nothing you can add to a VARCHAR2).
You can use interval partitioning with any suitable existing range partitioned table; that is, you can ALTER an existing range partitioned table to be interval partitioned, or you can create one with the CREATE TABLE command.
For example, suppose you had a range partitioned table that said “anything strictly less than 01-JAN-2021” (data in the year 2020 and before) goes into partition P1—and that was it.
So it had one partition for all data in the year 2020 and before. If you attempted to insert data for the year 2022 into the table, the insert would fail as demonstrated previously in the section on range partitioning.
With interval partitioning, you can create a table and specify both a range (strictly less than 01-JAN-2020) and an interval—say one month in duration—and the database would create monthly partitions (a partition capable of holding exactly one month’s worth of data) as the data arrived.
The database would not pre-create all possible partitions because that would not be practical. But, as each row arrived, the database would see whether the partition for the month in question existed. The database would create the partition if needed. Here is an example of the syntax:
$ sqlplus eoda/foo@PDB1
SQL> create table audit_trail( ts timestamp,data varchar2(30))partition by range(ts)interval (numtoyminterval(1,’month’))store in (users, example )(partition p0 values less than(to_date(’01-01-1900′,’dd-mm-yyyy’)));Table created.
Note You might have a question in your mind, especially if you just finished reading the previous chapter on datatypes. You can see we are partitioning by a TIMESTAMP, and we are adding an INTERVAL of one month to it. In Chapter 12, we saw how adding an INTERVAL of one month to a TIMESTAMP that fell on January 31 would raise an error, since there is no February 31. Will the same issue happen with interval partitioning? The answer is yes; if you attempt to use a date such as ’29-01-1990′ (any day of the month after 28 would suffice), you will receive an error “ORA-14767: Cannot specify this interval with existing high bounds”. The database will not permit you to use a boundary value that is not safe to add the interval to.
On lines 8 and 9, you see the range partitioning scheme for this table; it starts with a single empty partition that would contain any data prior to 01-JAN-1900. Presumably, since the table holds an audit trail, this partition will remain small and empty forever. It is a mandatory partition and is referred to as the transitional partition.
All data that is strictly less than this current high value partition will be range partitioned, using traditional range partitioning. Only data that is created above the transitional partition high value will use interval partitioning. If we query the data dictionary, we can see what has been created so far:
SQL> select a.partition_name, a.tablespace_name, a.high_value, decode( a.interval, ‘YES’, b.interval ) intervalfrom user_tab_partitions a, user_part_tables b where a.table_name = ‘AUDIT_TRAIL’ and a.table_name = b.table_nameorder by a.partition_position;
So far, we have just the single partition, and it is not an INTERVAL partition, as shown by the empty INTERVAL column. Rather, it is just a regular RANGE partition right now; it will hold anything strictly less than 01-JAN-1900.
Looking at the CREATE TABLE statement again, we can see the new interval partitioning–specific information on lines 6 and 7:interval (numtoyminterval(1,’month’))store in (users, example )
On line 6, we have the actual interval specification of NUMTOYMINTERVAL(1,’MONTH’). Our goal was to store monthly partitions—a new partition for each month’s worth of data—a very common goal. By using a date that is safe to add a month to (refer to Chapter 12 for why adding a month to a timestamp can be error-prone in some cases)— the first of the month—we can have the database create monthly partitions on the fly, as data arrives, for us.
On line 7, we have specifics: store in (users,example). This allows us to tell the database where to create these new partitions—what tablespaces to use. As the database figures out what partitions it wants to create, it uses this list to decide what tablespace to create each partition in. This allows the DBA to control the maximum desired tablespace size: they might not want a single 500GB tablespace, but they would be comfortable with ten 50GB tablespaces. In that case, they would set up ten tablespaces and allow the database to use all ten to create partitions. Let’s insert a row of data now and see what happens:
SQL> insert into audit_trail (ts,data) values ( to_timestamp(’27-feb-2020′,’dd-mon-yyyy’), ‘xx’ );1 row created.
SQL> select a.partition_name, a.tablespace_name, a.high_value, decode( a.interval, ‘YES’, b.interval ) intervalfrom user_tab_partitions a, user_part_tables b where a.table_name = ‘AUDIT_TRAIL’and a.table_name = b.table_nameorder by a.partition_position;
If you recall from the Range Partitioning section, you would expect that INSERT to fail. However, since we are using interval partitioning, it succeeds and, in fact, creates a new partition SYS_P1623. The HIGH_VALUE for this partition is 01-MAR-2020 which, if we were using range partitioning, would imply anything strictly less than 01-MAR-2020 and greater than or equal to 01-JAN-1900 would go into this partition, but since we have an interval, the rules are different. When the interval is set, the range for this partition is anything greater than or equal to the HIGH_VALUE-INTERVAL and strictly less than the HIGH_VALUE. So, this partition would have the range of
SQL> select TIMESTAMP’ 2020-03-01 00:00:00′-NUMTOYMINTERVAL(1,’MONTH’) greater_than_eq_to,