Partitioning is extremely useful in scaling up large database objects in the database. This scaling is visible from the perspective of performance scaling, availability scaling, and administrative scaling. All three are extremely important to different people.
The DBA is concerned with administrative scaling. The owners of the system are concerned with availability, because downtime is lost money, and anything that reduces downtime—or reduces the impact of downtime—boosts the payback for a system.
The end users of the system are concerned with performance scaling. No one likes to use a slow system, after all.
We also looked at the fact that in an OLTP system, partitions may not increase performance, especially if applied improperly. Partitions can increase the performance of certain classes of queries, but those queries are generally not applied in an OLTP system.
This point is important to understand, as many people associate partitioning with “free performance increase.” This does not mean that partitions should not be used in OLTP systems—they do provide many other salient benefits in this environment— just don’t expect a massive increase in throughput.
Expect reduced downtime. Expect the same good performance (partitioning will not slow you down when applied appropriately). Expect easier manageability, which may lead to increased performance due to the fact that some maintenance operations are performed by the DBAs more frequently because they can be.
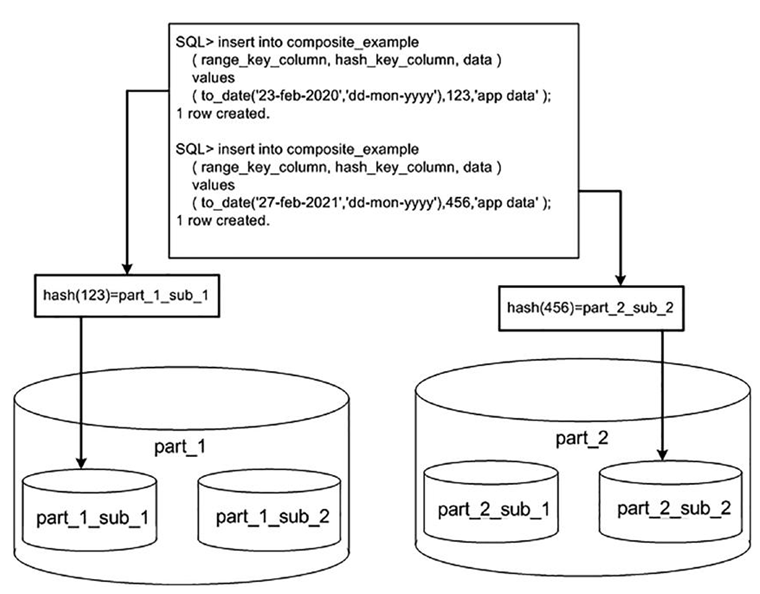
We investigated the various table partitioning schemes offered by Oracle—range, hash, list, interval, reference, interval reference, virtual column, and composite—and talked about when they are most appropriately used.
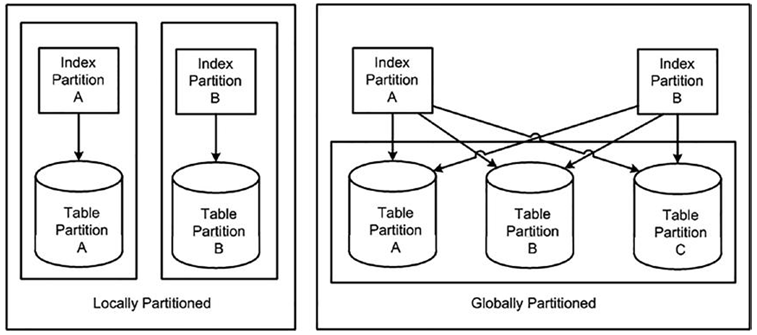
We spent the bulk of our time looking at partitioned indexes and examining the differences between prefixed and nonprefixed and local and global indexes. We investigated partition operations in data warehouses combined with global indexes, and the trade-off between resource consumption and availability.
We also looked at the ease of maintenance features such as the ability to perform maintenance operations on multiple partitions at a time, cascade truncate, and cascade exchange. Oracle continues to update and improve partitioning with each new release.
Over time, I see this feature becoming more relevant to a broader audience as the size and scale of database applications grow.
The Internet and its database-hungry nature along with legislation requiring longer retention of audit data are leading to more and more extremely large collections of data, and partitioning is a natural tool to help manage that problem.